25 核密度图
25.1 什么是核密度图?
核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parzen窗(Parzen window)。
核密度曲线类似于概率密度曲线,其曲线下的面积是1,因此其y轴上的单位通常是小于1的核密度分布值。对这个核密度曲线求积分的结果为1,也就是其曲线下的面积为1。实质是一种对直方图的抽象。
假设我们有n个数X1-Xn,我们要计算某一个数X的概率密度有多大。核密度估计的方法是这样的:
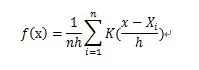
其中K为核密度函数,h为设定的窗宽。
核密度估计的原理其实是很简单的。在我们对某一事物的概率分布的情况下。如果某一个数在观察中出现了,我们可以认为这个数的概率密度很大,和这个数比较近的数的概率密度也会比较大,而那些离这个数远的数的概率密度会比较小。基于这种想法,针对观察中的第一个数,我们都可以f(x-xi)去拟合我们想象中的那个远小近大概率密度。当然其实也可以用其他对称的函数。针对每一个观察中出现的数拟合出多个概率密度分布函数之后,取平均。如果某些数是比较重要,某些数反之,则可以取加权平均。(解释来源:R语言中文社区)
25.2 绘图前的数据准备
demo数据可以在https://www.bioladder.cn/shiny/zyp/bioladder2/demoData/BoxPlot/boxplot.txt下载。
包含2个维度的数据,通常每一列是个样本,每一行是个基因
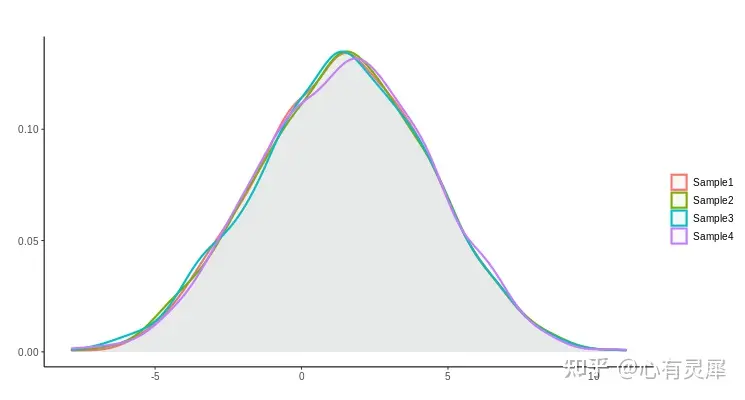
25.3 R语言怎么画核密度图
# 加载R包,没有安装请先安装 install.packages("包名")
library(ggplot2)
library(reshape2)
# 读取核密度图数据文件
df = read.delim("https://www.bioladder.cn/shiny/zyp/bioladder2/demoData/BoxPlot/boxplot.txt",# 这里读取了网络上的demo数据,将此处换成你自己电脑里的文件
header = T # 指定第一行是列名
)
# 把数据转换成ggplot常用的类型(长数据)
df = melt(df) # melt出自reshape2包
head(df) # 查看转换完成的数据的前几行
# 绘图
ggplot(df,aes(x=value,
fill=variable, # fill填充颜色,根据变量名赋值
colour=variable))+ # colour图形边界颜色,根据变量名赋值
geom_density(alpha=0.2, # 填充颜色透明度
size=1, # 线条粗细
linetype = 1 # 线条类型1是实线,2是虚线
)+
theme_bw() # 白色主题
# 补充知识:
# fill 一般是指填充颜色
# color 一般是指线和点的颜色
# colour 一般是指图形边界颜色25.4 BioLadder生信云平台在线绘制核密度图
不想写代码?可以用BioLadder生信云平台在线绘制核密度图。
网址: